Introduction
A vision-language-action model, often shortened to VLA, is an AI model that helps a robot connect three things: what it sees, what a person asks, and what physical action it should take next.
In simple terms, it is a model for turning perception and instructions into robot behavior. Instead of only answering a question about an image, a VLA model can output an action for a robot arm, hand, mobile base, or humanoid body.
Quick Answer
- A VLA model takes visual input, such as camera images, and language input, such as "pick up the blue cup."
- It predicts robot actions, such as moving an arm, opening a gripper, or stopping when the task is complete.
- The goal is to make robots easier to teach across objects, rooms, tasks, and robot bodies.
- VLA models are promising, but most are still research systems or early platform components, not fully reliable general-purpose robot brains.
Why This Matters
Traditional robots are strong in controlled settings. A factory robot can weld the same part thousands of times. A warehouse robot can follow a mapped route. A pick-and-place arm can move known objects if the lighting, gripper, camera, and item positions stay inside expected limits.
The hard part is generality. Real homes, hospitals, stores, farms, and mixed warehouses are messy. Objects move. People use loose instructions. A robot may need to understand that "put the snack in the bag" involves seeing the snack, finding the bag, choosing a grasp, moving safely, and checking the result.
VLA models are one answer to that problem. They try to bring the flexibility of vision-language AI into physical control. If they work well, robot developers could spend less time writing narrow task scripts and more time training or adapting broad robot policies.
What a VLA Model Does
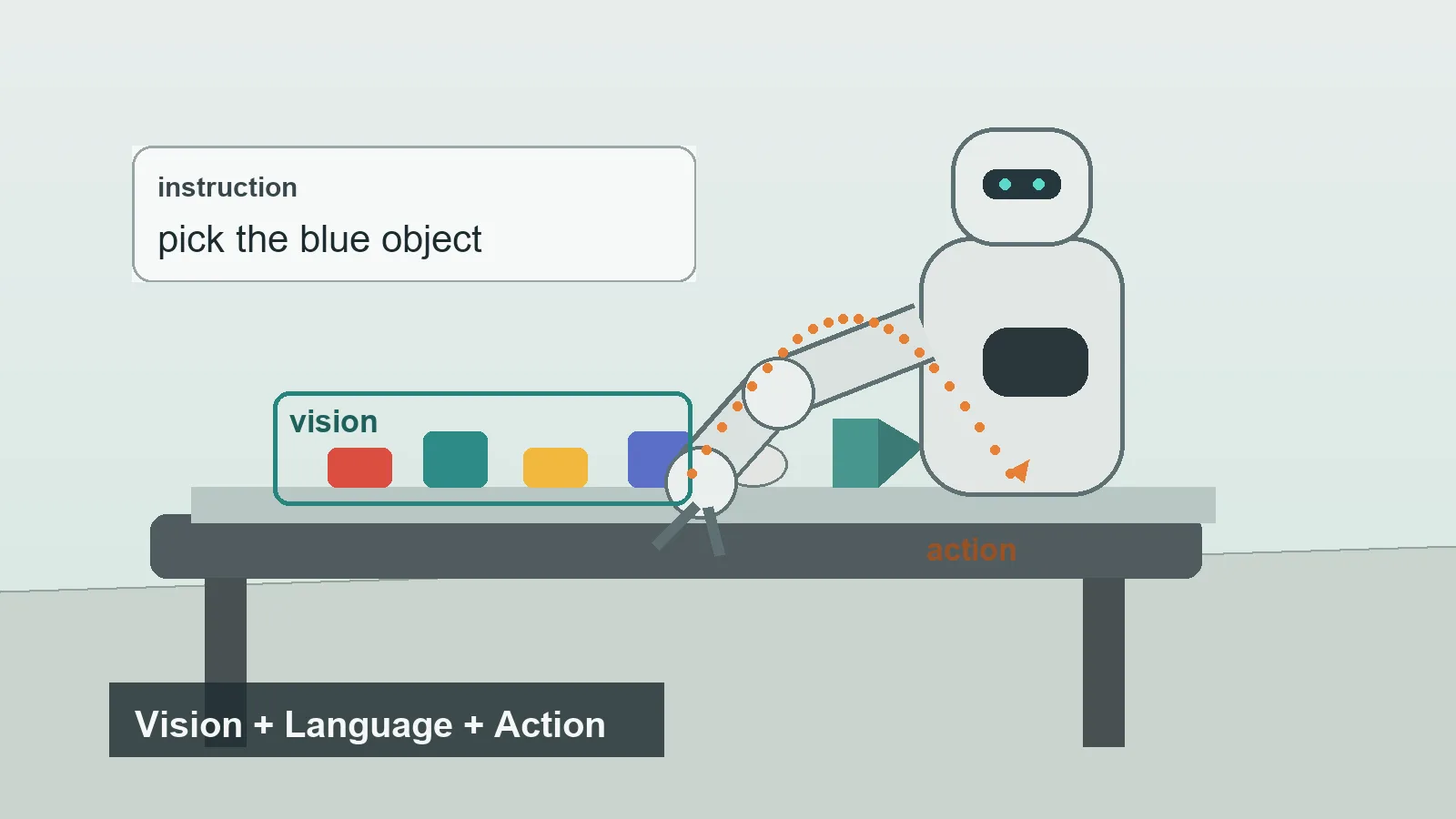
A VLA model combines three parts of a robot task.
Vision is the robot's view of the world. This usually comes from cameras, but it may also include depth sensors or other perception data. The model needs to identify objects, positions, obstacles, and scene context.
Language is the human instruction or task description. It may be a direct command like "move the apple into the bowl" or a more indirect phrase like "clean up the table."
Action is the robot's output. This may be a low-level control command, a gripper command, a sequence of motion tokens, or an action plan that another controller turns into movement.
The key difference from a normal vision-language model is the action output. A model that captions an image can say, "There is a cup on the table." A VLA model is designed to help the robot do something with that cup.
How It Works
The basic recipe is to train a large model on both internet-scale vision-language data and robot demonstration data.
The internet data helps the model learn broad visual and language concepts. For example, it may learn what cups, drawers, tools, fruit, packaging, shelves, hands, and rooms look like.
The robot data teaches the model how physical actions relate to those scenes. This data can come from teleoperation, human demonstrations, robot trials, simulation, or synthetic data. It shows the model what successful movement looks like for a specific robot or task family.
One important design idea is to represent robot actions in a form that a transformer model can learn. Google DeepMind's RT-2 work, announced in July 2023, described turning robot actions into tokens so a vision-language model could be trained to output actions for robotic control. OpenVLA later showed an open-source VLA model trained on a large collection of real-world robot demonstrations. NVIDIA's GR00T work applies related VLA ideas to humanoid robot skills.
The details differ across systems. Some models output discrete action tokens. Some use diffusion or flow-based policies for smoother control. Some produce high-level plans that are paired with lower-level controllers. But the common idea is the same: connect seeing, understanding, and acting in one learned policy.
A Simple Example
Imagine a robot arm facing a table with a red block, a blue cup, and a bowl.
A person says, "Put the blue cup in the bowl."
A traditional system might need a separate object detector, task parser, grasp planner, motion planner, and recovery rules. Each part can work well, but the full stack can be brittle when the object changes or the scene is unusual.
A VLA-style system tries to handle more of the mapping in one model:
- It sees the table through its camera.
- It connects the phrase "blue cup" to the correct object.
- It predicts a movement or sequence of movements.
- It closes the gripper, lifts the cup, moves toward the bowl, releases, and stops.
In practice, many systems still use safety layers, robot controllers, collision checking, and task-specific infrastructure around the model. A VLA model is not usually the whole robot stack. It is the learned policy that helps bridge instruction and action.
Where VLA Models Are Used
VLA models are most visible in manipulation research. This includes robot arms that pick, place, push, open, close, sort, and assemble objects.
Humanoid robots are another major target. A humanoid has many joints and may need to use two arms while balancing, looking around, and responding to speech. NVIDIA's GR00T N1 research describes a generalist humanoid model trained with human videos, real and simulated robot trajectories, and synthetic data. That kind of work shows why VLA models are closely tied to the broader "physical AI" conversation.
Warehouses and factories may also benefit, especially when robots need to handle varied products or follow natural-language instructions from workers. A VLA model could help a robot adapt to a new item, shelf layout, bin, or packing task. For safety and reliability, industrial deployments will still need strong validation before a broad VLA policy is allowed to act freely.
Service robots are a longer-term use case. Homes, hotels, hospitals, and public spaces are less structured than factories. A service robot may need broad scene understanding and careful action choices. VLA models are relevant here, but this is also where reliability, privacy, safety, and cost become especially difficult.
How VLA Differs From Related AI Terms
A vision-language model, or VLM, can understand images and text. It can answer questions about a scene, describe an object, or reason about visual content. A VLA model adds robot action.
A large language model, or LLM, mainly works with text. It can help plan tasks, write instructions, or control software tools. By itself, it does not know how to move a robot arm safely through space.
Embodied AI is the broader field of AI systems that perceive and act in physical or simulated environments. VLA models are one technical path inside embodied AI.
Physical AI is a broad industry term for AI that reasons about and acts in the physical world. VLA models are one practical building block for physical AI, especially in robotics.
Why VLA Models Are Hard
The first challenge is data. Text and image data are abundant on the web. Robot action data is much harder to collect. Every robot has different joints, grippers, cameras, control rates, and safety limits. A dataset from one arm may not transfer cleanly to another arm.
The second challenge is embodiment. A wheeled mobile robot, a single arm, a dual-arm humanoid, and a quadruped do not act the same way. A general VLA model must either learn across bodies or be adapted carefully for each body.
The third challenge is reliability. A chatbot can be wrong and still be recoverable. A robot action can drop an object, damage equipment, or create a safety hazard. VLA models need guardrails, testing, fallback behavior, and clear limits.
The fourth challenge is evaluation. It is easy to show a compelling demo. It is much harder to prove that a robot works across thousands of homes, warehouses, tools, lighting conditions, and edge cases.
What To Watch
Watch whether VLA models become easier to fine-tune for new robots and tasks. Open models such as OpenVLA point toward a more accessible research ecosystem, while platform efforts from companies such as NVIDIA point toward reusable infrastructure for humanoids and physical AI.
Also watch action representations. The field is still exploring whether robot actions should be treated as tokens, continuous trajectories, diffusion-style outputs, hierarchical plans, or some combination of these.
Finally, watch deployment claims carefully. A VLA model can be impressive in a lab and still not be ready for unsupervised work in a busy real environment. The most useful signal is not a single demo. It is repeatable performance across varied tasks, clear safety boundaries, and evidence that the model can recover when the world does not match the training data.
FAQ
What does VLA stand for in robotics?
VLA stands for vision-language-action. It refers to models that use visual input and language instructions to predict robot actions.
Is a VLA model the same as a robot foundation model?
Not always. A robot foundation model is a broader term for a general model trained for robotics. Many robot foundation models use VLA ideas, but a foundation model may include other architectures, planning methods, or world models.
Can VLA models control real robots today?
Yes, research systems and platform models have demonstrated real robot control. However, broad commercial reliability is still an open problem, especially in unstructured environments.
Why do VLA models need robot data?
Vision-language data can teach a model about objects and concepts, but robot data teaches how actions change the physical world. Without action data, the model may understand a scene but not know how to move a specific robot safely and effectively.
Are VLA models only for humanoid robots?
No. They can be used with robot arms, mobile manipulators, humanoids, and other embodiments. Humanoids get attention because they need broad, language-conditioned physical skills, but manipulation tasks are currently one of the most active VLA research areas.