简介
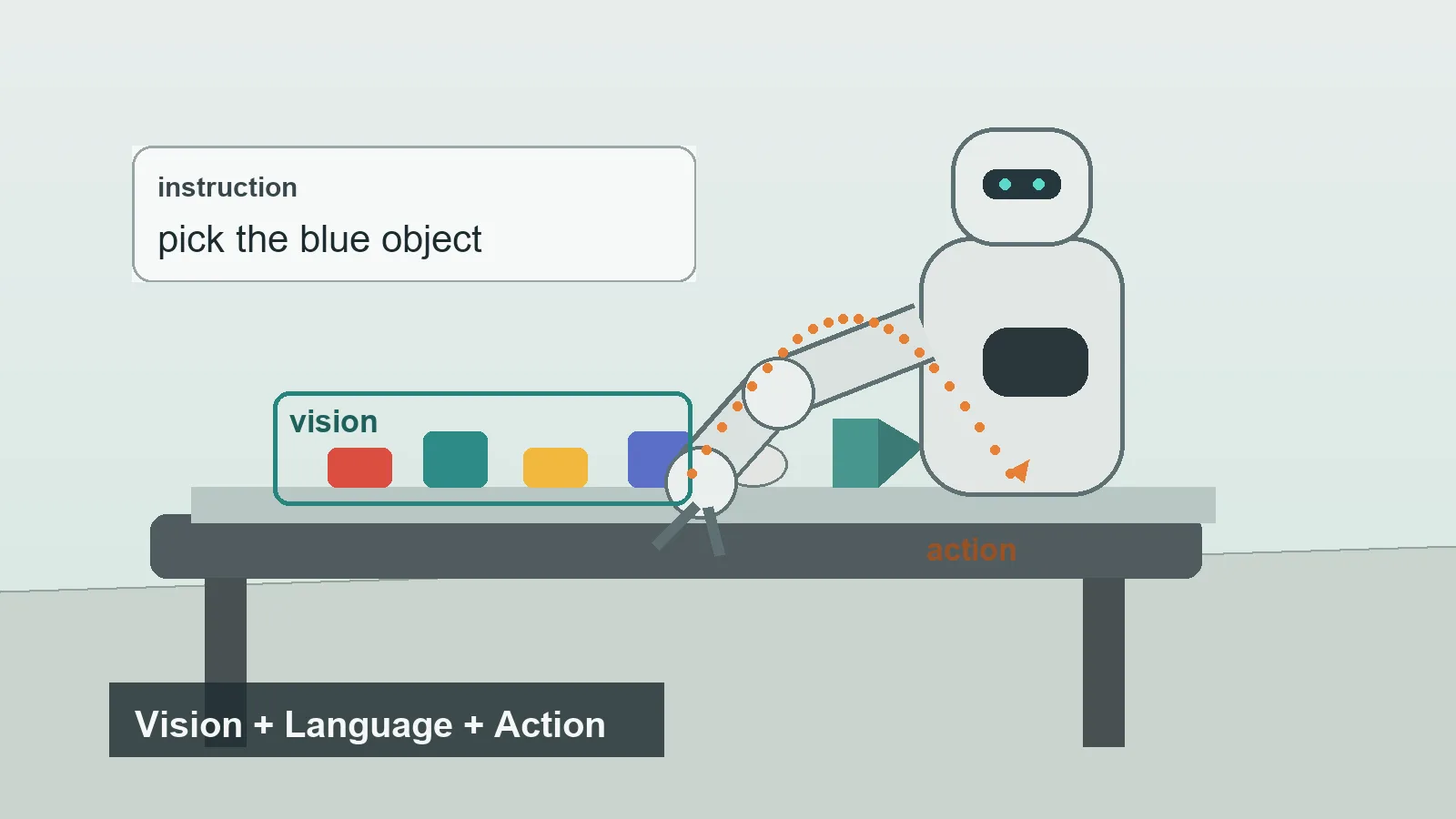
视觉-语言-动作模型通常简称VLA。它是一类AI模型,用来帮助机器人把三件事连接起来:它看到了什么、人让它做什么,以及下一步应该执行什么物理动作。
简单来说,VLA模型把感知和指令转化为机器人行为。它不只是回答一张图片里有什么,还可以为机械臂、夹爪、移动底盘或人形机器人身体输出动作。
快速回答
- VLA模型会接收视觉输入,例如摄像头图像,也会接收语言输入,例如“拿起蓝色杯子”。
- 它会预测机器人动作,例如移动机械臂、打开夹爪,或在任务完成时停止。
- 目标是让机器人更容易跨物体、房间、任务和机器人本体进行学习。
- VLA模型很有前景,但多数仍是研究系统或早期平台组件,还不是完全可靠的通用机器人“大脑”。
为什么这件事重要
传统机器人擅长受控环境。工厂机器人可以把同一个零件焊接上千次。仓库机器人可以沿着已建图路线行驶。只要光照、夹爪、相机和物品位置都在预期范围内,抓取放置机械臂就能移动已知物体。
难点在于泛化。真实家庭、医院、商店、农场和混合仓库都很复杂。物体会移动。人的指令也往往不精确。机器人可能需要理解“把零食放进袋子”意味着先看到零食,找到袋子,选择抓取方式,安全移动,并检查结果。
VLA模型正是这个问题的一种解法。它们试图把视觉-语言AI的灵活性带入物理控制。如果这类模型足够可靠,机器人开发者就可以少写很多狭窄任务脚本,把更多精力放在训练或适配更通用的机器人策略上。
VLA模型做什么
VLA模型把机器人任务中的三个部分结合在一起。
视觉是机器人对世界的观察。它通常来自摄像头,也可能包括深度传感器或其他感知数据。模型需要识别物体、位置、障碍物和场景上下文。
语言是人的指令或任务描述。它可以是“把苹果移到碗里”这样的直接命令,也可以是“把桌子收拾一下”这样的间接表达。
动作是机器人的输出。它可以是低层控制命令、夹爪命令、一串运动token,或一个由其他控制器转化为运动的动作计划。
它与普通视觉-语言模型的关键区别在于动作输出。一个给图片写说明的模型可以说:“桌子上有一个杯子。”VLA模型的目标,是帮助机器人对那个杯子做点什么。
它如何工作
基本做法是用互联网规模的视觉-语言数据和机器人演示数据共同训练一个大模型。
互联网数据帮助模型学习广泛的视觉和语言概念。例如,它可能学会杯子、抽屉、工具、水果、包装、货架、手和房间是什么样子。
机器人数据则教模型理解物理动作与这些场景之间的关系。这些数据可以来自遥操作、人类演示、机器人试验、仿真或合成数据。它们告诉模型,对某一种机器人或某一类任务来说,成功的运动是什么样的。
一个重要设计思路是,把机器人动作表示成transformer模型能够学习的形式。Google DeepMind在2023年7月发布的RT-2工作中,描述了如何把机器人动作转化为token,让视觉-语言模型能够训练出用于机器人控制的动作输出。后来的OpenVLA展示了一个开源VLA模型,训练数据来自大规模真实机器人演示。NVIDIA的GR00T工作则把相关VLA思路用于人形机器人技能。
不同系统的细节并不一样。有些模型输出离散动作token。有些使用扩散或flow-based策略来获得更平滑的控制。有些生成高层计划,再交给低层控制器执行。但共同思路相同:用一个学习到的策略,把看见、理解和行动连接起来。
一个简单例子
想象一个机械臂面对一张桌子,桌上有红色积木、蓝色杯子和一个碗。
人说:“把蓝色杯子放进碗里。”
传统系统可能需要单独的物体检测器、任务解析器、抓取规划器、运动规划器和恢复规则。每一部分都可以做得很好,但当物体变化或场景不寻常时,完整系统仍可能变得脆弱。
VLA风格的系统会尝试在一个模型中处理更多映射关系:
- 它通过摄像头看到桌面。
- 它把“蓝色杯子”这句话对应到正确物体。
- 它预测一个动作或一串动作。
- 它闭合夹爪,提起杯子,移动到碗旁,松开,然后停止。
在实际系统中,模型周围通常仍会有安全层、机器人控制器、碰撞检查和任务专用基础设施。VLA模型通常不是完整机器人系统本身。它是一个学习到的策略,用来连接指令和动作。
VLA模型用在哪里
VLA模型最常出现在操作任务研究中。这包括让机械臂抓取、放置、推动、打开、关闭、分类和组装物体。
人形机器人是另一个重要目标。人形机器人有很多关节,可能需要在保持平衡、观察周围和响应语音的同时使用双臂。NVIDIA的GR00T N1研究描述了一种通用人形机器人模型,训练数据包括人类视频、真实和仿真的机器人轨迹,以及合成数据。这类工作也说明,为什么VLA模型与更广泛的“Physical AI”讨论密切相关。
仓库和工厂也可能受益,尤其是在机器人需要处理多样产品,或根据工人的自然语言指令行动时。VLA模型可以帮助机器人适应新的物品、货架布局、料箱或打包任务。出于安全和可靠性考虑,工业部署仍需要严格验证,不能让宽泛的VLA策略在没有边界的情况下自由行动。
服务机器人是更长期的应用场景。家庭、酒店、医院和公共空间比工厂更不结构化。服务机器人需要更广泛的场景理解,也需要谨慎选择动作。VLA模型与这些场景相关,但可靠性、隐私、安全和成本在这里也会变得尤其困难。
VLA与相关AI术语有什么不同
视觉-语言模型,也就是VLM,可以理解图像和文本。它可以回答场景问题、描述物体,或对视觉内容进行推理。VLA模型在此基础上增加了机器人动作。
大语言模型,也就是LLM,主要处理文本。它可以帮助规划任务、编写指令,或控制软件工具。但仅靠LLM本身,它并不知道如何让机械臂安全地穿过空间。
Embodied AI是一个更宽泛的领域,指能在物理或仿真环境中感知并行动的AI系统。VLA模型是Embodied AI中的一条技术路径。
Physical AI是行业中常用的宽泛概念,指能够理解物理世界并在其中行动的AI。VLA模型是Physical AI的一个实用组成部分,尤其适用于机器人。
为什么VLA模型很难
第一个挑战是数据。文本和图像数据在网络上非常丰富。机器人动作数据则难得多。每种机器人都有不同的关节、夹爪、相机、控制频率和安全限制。一台机械臂的数据集不一定能顺利迁移到另一台机械臂。
第二个挑战是本体。轮式移动机器人、单臂机器人、双臂人形机器人和四足机器人并不会以同一种方式行动。通用VLA模型要么必须跨本体学习,要么需要针对每一种本体谨慎适配。
第三个挑战是可靠性。聊天机器人答错了,通常还有补救空间。机器人动作出错,则可能摔落物体、损坏设备,或造成安全风险。VLA模型需要护栏、测试、回退行为和清晰边界。
第四个挑战是评估。展示一个吸引人的演示很容易。证明一个机器人能在成千上万的家庭、仓库、工具、光照条件和边界情况中稳定工作,要难得多。
接下来要看什么
首先要看VLA模型是否会更容易为新机器人和新任务微调。OpenVLA这样的开放模型指向了更易进入的研究生态,而NVIDIA等公司的平台化努力,则指向可复用的人形机器人和Physical AI基础设施。
也要关注动作表示方式。这个领域仍在探索机器人动作究竟应该被表示为token、连续轨迹、扩散式输出、层级计划,还是这些方法的组合。
最后,要谨慎看待部署声明。VLA模型可以在实验室里表现惊艳,但仍未必能在繁忙真实环境中无人监督地工作。最有价值的信号不是单个演示,而是在多样任务上的可重复表现、清晰的安全边界,以及当世界与训练数据不一致时模型能否恢复。
FAQ
机器人领域的VLA是什么意思?
VLA代表vision-language-action,即视觉-语言-动作。它指的是使用视觉输入和语言指令来预测机器人动作的模型。
VLA模型和机器人基础模型是一回事吗?
不一定。机器人基础模型是更宽泛的说法,指为机器人训练的通用模型。许多机器人基础模型使用VLA思路,但基础模型也可能包含其他架构、规划方法或世界模型。
VLA模型现在能控制真实机器人吗?
可以,研究系统和平台模型已经展示过真实机器人控制。不过,广泛商业可靠性仍是开放问题,尤其是在非结构化环境中。
为什么VLA模型需要机器人数据?
视觉-语言数据可以教模型认识物体和概念,但机器人数据教它动作如何改变物理世界。没有动作数据,模型可能理解场景,却不知道如何安全、有效地移动某一台具体机器人。
VLA模型只用于人形机器人吗?
不是。它们可以用于机械臂、移动操作机器人、人形机器人和其他本体。人形机器人受到关注,是因为它们需要广泛的、由语言条件驱动的物理技能,但操作任务目前仍是VLA研究最活跃的方向之一。